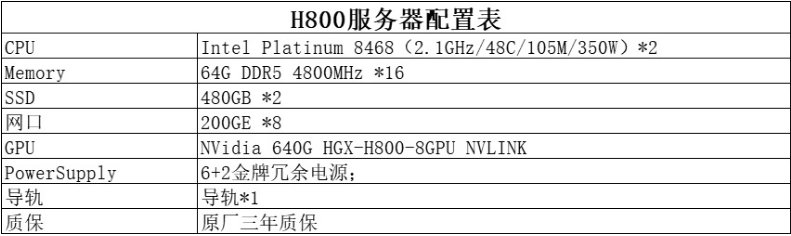

通过 NVIDIA H800 Tensor Core GPU,在每个工作负载中实现出色性能、可扩展性和安全性。使用 NVIDIA® NVLink® Switch 系统,可连接多达 256 个 H800 来加速百亿亿级 (Exascale) 工作负载,另外可通过专用的 Transformer 引擎来处理万亿参数语言模型。与上一代产品相比,H800 的综合技术创新可以将大型语言模型的速度提高 30 倍,从而提供业界领先的对话式 AI。
通过 NVIDIA H800 Tensor Core GPU,在每个工作负载中实现出色性能、可扩展性和安全性。使用 NVIDIA® NVLink® Switch 系统,可连接多达 256 个 H800 来加速百亿亿级 (Exascale) 工作负载,另外可通过专用的 Transformer 引擎来处理万亿参数语言模型。与上一代产品相比,H800 的综合技术创新可以将大型语言模型的速度提高 30 倍,从而提供业界领先的对话式 AI。
变革 AI 训练
H800 配备第四代 Tensor Core 和 Transformer 引擎(FP8 精度),与上一代产品相比,可为多专家 (MoE) 模型提供高 9 倍的训练速度。通过结合可提供 400 GB/s GPU 间互连的第四代 NVlink、可跨节点加速每个 GPU 通信的 NVLINK Switch 系统、PCIe 5.0 以及 NVIDIA Magnum IO™ 软件,为小型企业到大规模统一 GPU 集群提供高效的可扩展性。
在数据中心级部署 H800 GPU 可提供出色的性能,并使所有研究人员均能轻松使用新一代百亿亿次级 (Exascale) 高性能计算 (HPC) 和万亿参数的 AI。
实时深度学习推理
AI 正在利用一系列广泛的神经网络解决范围同样广泛的一系列商业挑战。出色的 AI 推理加速器不仅要提供非凡性能,还要利用通用性加速这些神经网络。
H800 进一步扩展了 NVIDIA 在推理领域的市场领先地位,其多项先进技术可将推理速度提高 30 倍,并提供超低的延迟。第四代 Tensor Core 可加速所有精度(包括 FP64、TF32、FP32、FP16 和 INT8)。Transformer 引擎可结合使用 FP8 和 FP16 精度,减少内存占用并提高性能,同时仍能保持大型语言模型的准确性。
百亿亿次级高性能计算
NVIDIA 数据中心平台性能持续提升,超越摩尔定律。H800 的全新突破性 AI 性能进一步加强了 HPC+AI 的力量,加速科学家和研究人员的探索,让他们全身心投入工作,解决世界面临的重大挑战。
H800 还采用 DPX 指令,其性能比 NVIDIA A800 Tensor Core GPU 高 7 倍,在动态编程算法(例如,用于 DNA 序列比对 Smith-Waterman)上比仅使用传统双路 CPU 的服务器快 40 倍。
加速数据分析
在 AI 应用开发过程中,数据分析通常会消耗大部分时间。原因在于,大型数据集分散在多台服务器上,由仅配备商用 CPU 服务器组成横向扩展式的解决方案缺乏可扩展的计算性能,从而陷入困境。
搭载 H800 的加速服务器可以提供相应的计算能力,并利用 NVLink 和 NVSwitch 每个 GPU 3 TB/s 的显存带宽和可扩展性,凭借高性能应对数据分析以及通过扩展支持庞大的数据集。通过结合使用 NVIDIA Quantum-2 InfiniBand、Magnum IO 软件、GPU 加速的 Spark 3.0 和 NVIDIA RAPIDS™,NVIDIA 数据中心平台能够以出色的性能和效率加速这些大型工作负载
咨询资源详情请联系:18822175630
 188-1059-2009
188-1059-2009传真:
E-mail:s91@linktom.com
qq1:微信(手机同号) qq2: qq3:
地址:北京市海淀区苏州街18号长远天地大厦B1座6层606
版权所有 ©2015-2023 zzcms.com 京ICP备09009921号-4







